Data Equity Framework
Data = numbers, so where does equity fit in?
Isn’t the point of using data that I can get unbiased, objective answers to my questions? No. In fact, we can do so much better than that. If you’re a quantitative data expert who has outgrown the restrictive formulas and cookie cutter recipes, this framework is for you. If you’ve been interacting with data in your work and you just can’t shake the feeling that it might be actually messing things up for the people you care about… good news, you’re not crazy. Welcome to The Data Equity Framework!
A data project is pretty much a series of incredibly important choices…
And there isn’t one right answer. Choices like “how should we define “homelessness?”, “how big of a sample size do we need?”, “how should we control for this variable?”, “where do we think that our results apply?”, etc don’t have a single right answer for everyone in every situation, but they DO have an answer that’s right for your project and the populations for whom you are trying to make meaning. The quality of your choice making will dictate the quality of your work.
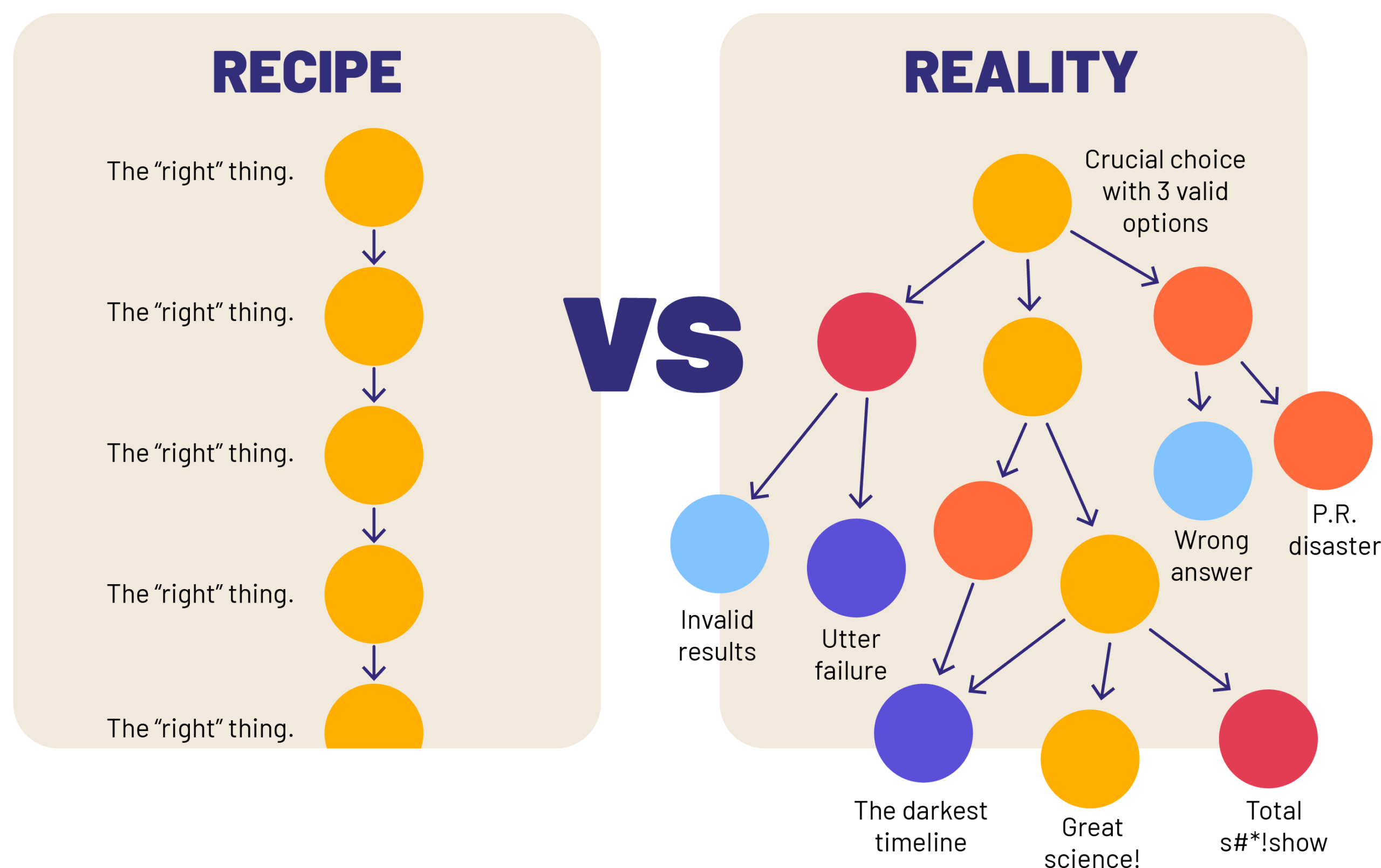
We need to make these choices…
Each card is a button. Activate the front of a card to flip it and
read the additional text, then activate the back of the same card to
return to the front. Press Escape to return all cards to their front
side.
Accurately
Rigorously
Repeatably
Equitably
We need a systemic approach to improving our choice making…
(good start)
Level 1: Notice
Only the first step and still about a billion times better science and equity than before. The first step is the most important. If you aren’t aware that you are making a crucial, subjective choice, you’re almost guaranteed to screw it up. We need a regular, repeatable approach to anticipate and address these crucial choices so we’re not reacting to them, or worse missing them all together.
(now we’re talkin’)
Level 2: Document
Showing your work isn’t a sign of great science, it is the science. Before we rush off to make a “better” choice, you need to have ways to document how a choice is made and what choice was made. Even if we change nothing, this internal clarity and scientifically necessary part of the process is a huge improvement to the equity of your project.
(honestly, incredible)
Level 3: Communicate
Without the tools to discuss these choices internally and explain them externally, we’re not gaining much. Even without changing how we make choices, we can reap the fruits of our labor in the previous steps. Being able to defend our compromises, explain our parameters, and prove that we are thinking about these critical choices and their equity implications is a great opportunity to generate trust in our work. We can demonstrate our careful and precise care for our stakeholders.
This is also an unskippable step in a serious scientific process. Without communicating key decisions, parameters, and assumptions, no one know what our results even really mean, much less if they can be relied upon.
(choice mastered, hero level!)
Level 4: Align
Aligning our choices with our unique equity goals just got a lot easier. Now that we can identify, record, and talk about a choice, we can change it for the better. Whose “better”? The better that works for our project and the people we are doing it for.
Every project is going to have its own set of goals, benefits, and success criteria. We want tools and systems to make sure they come to fruition for everyone who needs them!
You need a framework that reduces overwhelm.
Working in data means making hundreds if not thousands of subjective choices throughout a project. That might be one person working in a basement, that might be a ten person department of a company, or an whole agency of a government. You can’t try to address every choice, all at the same time.
The Data Equity Framework breaks out all data work into 7 Key Stages, that come with similar sets of choices, natural punctuation points, and a logical “this affects that” order.

Funding
If you want to get a handle on the power dynamics in your data project, you need to get the money straight.
This step involves mapping the flow of money, data and decision making; crafting the relationship you want with the people who supply your data; and insuring that the fruits of your labor go to all the people you want them to!

Motivation
Entrenching your goals right into the heart of your project is the best way to make sure that they don’t get lost in the shuffle.
Create a rock solid, scientifically rigorous touchstone, used to make every mathematical and human decision that pops up in your project with consistent and sharp focus on what matters most to you.

Project Design
You can craft a plan that gets you robust answers to your actual questions.
Explore and select methodologies, metrics, indicators, denominators, research questions, and sample approaches that align your science parameters with the people you are trying to make meaning for.

Data Collection
& Sourcing
Dig into how your data – whether first or second hand – gets collected, processed, sorted and categorized.
Deal with demographic and identity data with confidence rather than uncertainty. Use tools that not only make better decisions in these difficult areas, but can bring concerned stakeholders on-side.

Analysis
How we analyze, calculate, and model with our data is the true core of each project, and the most sensitive moment for data equity.
This is the moment where we can make sure that our commitment to our stakeholders is baked into the math, not just lip service.

Interpretation
As the numbers get translated back into conceptual meaning, you need a repeatable system for making sure that nothing got garbled in translation.
Ensure consistency across methodology, certainty levels, key definitions and external relevance to arrive at meaningful information you can stand behind 100%.

Communication
& Distribution
Entrenching your goals right into the heart of your project is the best way to make sure that they don’t get lost in the shuffle.
Create a rock solid, scientifically rigorous touchstone, used to make every mathematical and human decision that pops up in your project with consistent and sharp focus on what matters most to you.