Resources Hub
Data Equity in Practice
Welcome to the Resource Hub: your friendly home base for doing data equity with substance. Everything here is built to be useful, not performative; practical, not precious. You’ll find tools that invite collaboration, stories that build connection, and ideas that spark innovation without losing rigor. Dip in, share with your team, and make it your working library.
How the Collections work
Collections are curated pathways through the noise. Use Getting Started for orientation, Hot Topics for fresh thinking, Real World Stories for grounded examples, Telling Better Data Stories for communication craft, Designing a Survey for participant-respecting methods, Impact Evaluation for evidence that matters, and Talk to Your Boss for ready-to-use persuasion.
How the Tags help
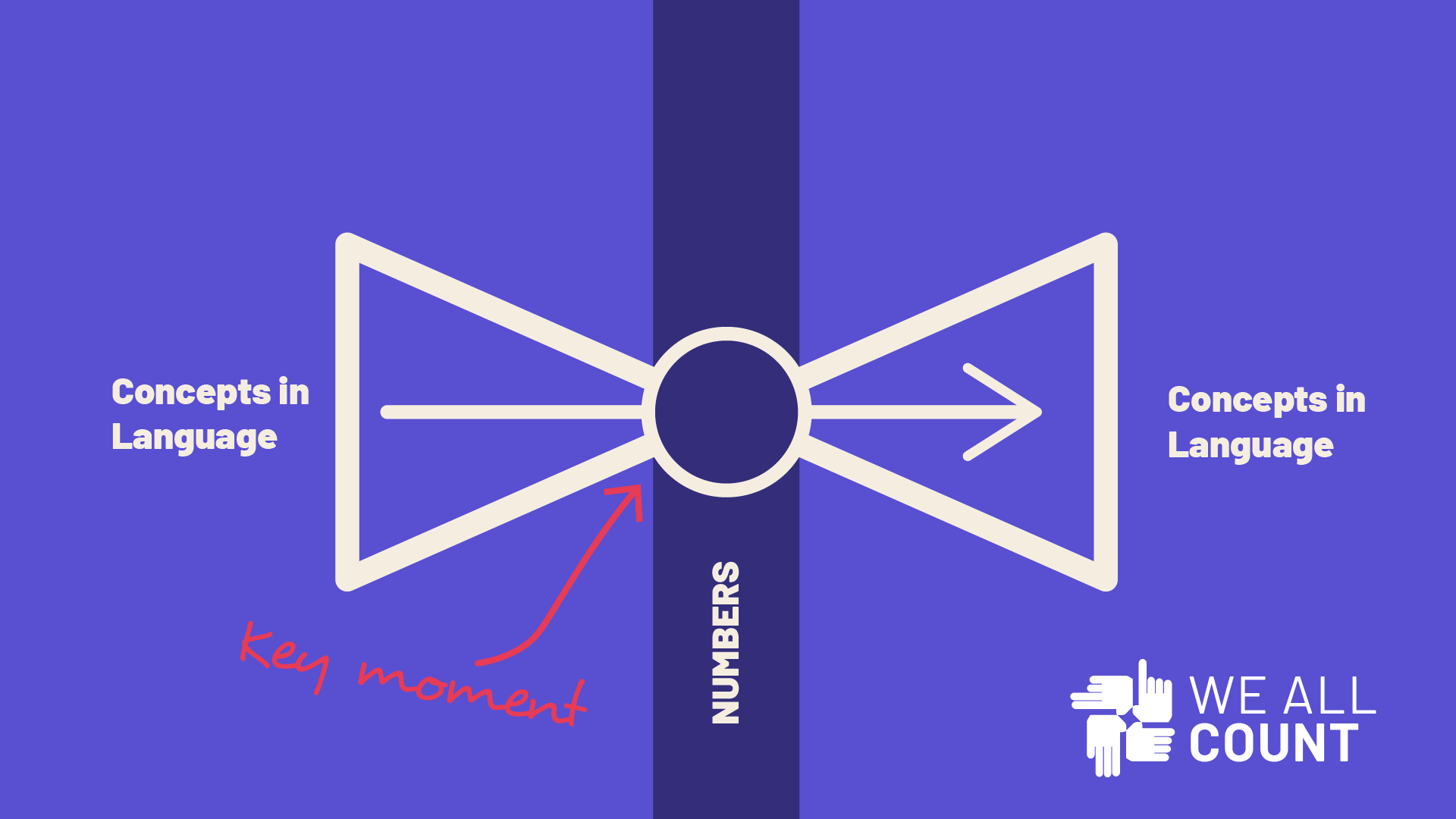
Tags make it easy to pinpoint what you need. General tags flag format and authorship (e.g., Free Resource, Case Study, Guest Author/Interview, Research Brief). Framework tags map directly to our seven steps—Funding, Motivation, Project Design, Data Collection, Analysis, Interpretation, Communication—and are visually distinct so you can trace any resource to the exact decision it supports.
Getting Started
Introducing data equity and the data equity framework


Hot Topics
New tools, new examples, data that’s happening now



Telling Better Data Stories
Communicating evidence with rigor and equity



Browse All Articles
The complete catalog of resources and examples